Kubernetes Reusable Elements for Designing Cloud Native Applications: Foundational Patterns

Kubernetes Foundational Patterns are reusable design principles and best practices for building applications that run on Kubernetes. They are not specific to any programming language, framework, or domain. Rather, they provide general guidance and recommendations for common challenges and scenarios that you may encounter when developing and deploying applications on Kubernetes.
Predictable Demands

The Predictable Demands pattern is a fundamental principle of Kubernetes that ensures your applications comply with the core principles of containerized apps, making them ready to be automated using Kubernetes. This pattern is about declaring application requirements, whether they are hard runtime dependencies or resource requirements.
The pattern is based on the idea that every container in a Kubernetes cluster should declare its resource requirements and limits, such as CPU, memory, disk, and network. By doing so, the container can communicate to Kubernetes what it needs to run properly, and Kubernetes can allocate resources accordingly, as well as enforce quality of service (QoS) policies and prevent resource starvation or contention.
The predictable demands pattern has several benefits for both the application and the cluster. For the application, it ensures that the container has enough resources to perform its tasks, and that it does not consume more resources than it should. This can improve the performance, reliability, and stability of the application, as well as reduce the risk of errors or failures due to insufficient or excessive resource usage. For the cluster, it enables Kubernetes to optimize the resource utilization and distribution across the nodes, and to balance the load and avoid overcommitment or underutilization. This can enhance the scalability, efficiency, and resilience of the cluster, as well as simplify the monitoring and troubleshooting of resource-related issues.
Declarative Deployment
Declarative deployment is a way of installing or updating applications in Kubernetes by describing the target state of the system, such as the number of replicas, the image version, the configuration, and the resources. Kubernetes then takes care of creating, scaling, updating, and deleting the underlying resources (Pods, ReplicaSets, Services, etc.) to match the desired state.
Declarative deployment is different from imperative deployment, which involves issuing commands or scripts that perform specific actions on the system, such as creating a Pod, scaling a ReplicaSet, or rolling back a Deployment. Imperative deployment requires more knowledge and control over the details of the system, but also introduces more complexity and potential errors.
Rolling Deployment

Rolling deployment is a technique of updating an application by gradually replacing the old version with the new one. Instead of stopping the entire application and deploying the new version at once, rolling deployment updates the application in batches, one pod at a time. This way, the application remains available and responsive during the update process.
Fixed Deployment

The idea behind of the fixed deployment pattern involves stopping all the containers that run the old version of the application and creating new containers with the new version. This means that there is a period of time when no application instance is available to process requests, resulting in an outage for the clients. A fixed deployment is suitable for applications that can tolerate downtime or have low availability requirements. However, it’s not recommended for applications that need high availability or zero downtime.
The RollingUpdate strategy ensures no downtime during updates, but it runs 2 versions of the container simultaneously. This can cause issues if the update introduces backward-incompatible changes and the client can’t handle them.
On the other hand, the Recreate strategy first stops all current containers before starting new ones. This results in downtime, but only one version of the container runs at a time, ensuring clients connect to only one version.
Blue-Green Release

Blue-Green deployment is a release strategy that minimizes downtime and risk during software deployment in production environments. It utilizes Kubernetes Deployment abstraction, which allows for seamless transitioning between immutable container versions.
In this strategy, a second Deployment (green) is created with the latest container version, while the original Deployment (blue) continues to serve live requests. Once the new version is deemed healthy, traffic is switched from the blue to the green containers by updating the Service selector.
The advantage of this approach is that only one application version serves requests at a time, simplifying service consumption. However, it requires double the application capacity and can lead to complications with long-running processes and database state drifts during transitions.
Canary Release

Canary release is a deployment strategy that minimizes the risk of introducing a new application version by initially replacing only a small number of old instances. This allows a subset of users to interact with the updated version. If the new version performs well, all old instances are replaced.
In Kubernetes, this is achieved by creating a new Deployment with a small replica count for the canary instance. The Service then directs some users to the updated Pod instances. Once confident in the new ReplicaSet, it’s scaled up and the old ReplicaSet is scaled down, effectively executing a controlled, user-tested incremental rollout.
Health Probe

The Health Probe pattern is a way for an application to communicate its health state to Kubernetes, which can then take appropriate actions based on the application’s status. For example, Kubernetes can restart a container that is not responding, or remove a pod that is not ready from a service’s load balancer. The Health Probe pattern enables a cloud-native application to be more resilient and scalable by allowing Kubernetes to manage its lifecycle and traffic routing.
Liveness Probes

A liveness probe is used to check if a container is alive or dead. A container is considered alive if it can respond to the liveness probe within a specified timeout. A container is considered dead if it fails to respond to the liveness probe for a certain number of times consecutively.
Kubernetes uses liveness probes to determine when to restart a container. If a container fails its liveness probe, Kubernetes will kill it and create a new one. This can help recover from situations where a container becomes unresponsive or hangs due to a deadlock or a resource exhaustion.
To configure a liveness probe, you need to specify how Kubernetes should perform the probe, how often it should perform it, how long it should wait for a response, and how many failures it should tolerate before restarting the container.
Readiness Probes

Readiness probes are used to signal when an application is ready to start accepting traffic. Kubernetes will periodically execute a readiness probe on a container, and if the probe succeeds, it will add the container to the service endpoint and allow it to receive traffic. If the probe fails, it will remove the container from the service endpoint and stop sending traffic to it.
Readiness probes are useful for scenarios where an application needs some time to warm up before serving requests, or where an application may become temporarily overloaded or degraded and needs to shield itself from additional load. For example, a web server may need to load configuration files or establish database connections before it can handle HTTP requests, or a microservice may need to throttle requests when its latency increases due to high load or downstream failures.
Startup Probes

Startup probes are a type of probe that can be used to check if an application has successfully started within a pod. Startup probes are useful for applications that take a long time to initialize, or that perform some initialization tasks before being ready to accept requests. For example, an application may need to load a large amount of data into memory, or connect to a remote database, or perform some schema migrations. These tasks can take longer than the default timeout period of 10 seconds that Kubernetes uses to determine if a pod is healthy. If the pod fails to respond to the liveness probe within this period, Kubernetes will kill and restart the pod, assuming that it is stuck or dead. This can result in a never-ending loop of restarts, preventing the application from ever becoming ready.
Startup probes can help avoid this situation by telling Kubernetes to wait for a longer period before performing the liveness checks. Startup probes work by sending an HTTP GET request, a TCP socket connection, or an arbitrary command execution to the pod, and expecting a success response. The startup probe can be configured with parameters such as initialDelaySeconds, periodSeconds, timeoutSeconds, successThreshold, and failureThreshold, which control how often and how long the probe should run. The startup probe will run until it succeeds, or until it reaches the failureThreshold. If the startup probe succeeds, Kubernetes will start performing the liveness and readiness probes as usual. If the startup probe fails, Kubernetes will kill and restart the pod as usual.
Managed Lifecycle

Cloud-native applications need to adjust their lifecycles in response to platform events. They provide APIs for health checks and respond to platform commands. The deployment unit of an application is a Pod, which consists of one or more containers.
Kubernetes manages the container lifecycle. When it decides to shut down a container, it sends a SIGTERM signal, and if the application doesn’t shut down, a SIGKILL signal is sent after a grace period.
Kubernetes also provides features like PostStart Hook and PreStop Hook. The PostStart Hook runs after a container is created, while the PreStop Hook is sent before a container is terminated.
Init containers run before any application containers in a Pod and are used for Pod-level initialization tasks. For more control over the startup process, methods like the Commandlet pattern and Entrypoint Rewriting can be used.
Automated Placement
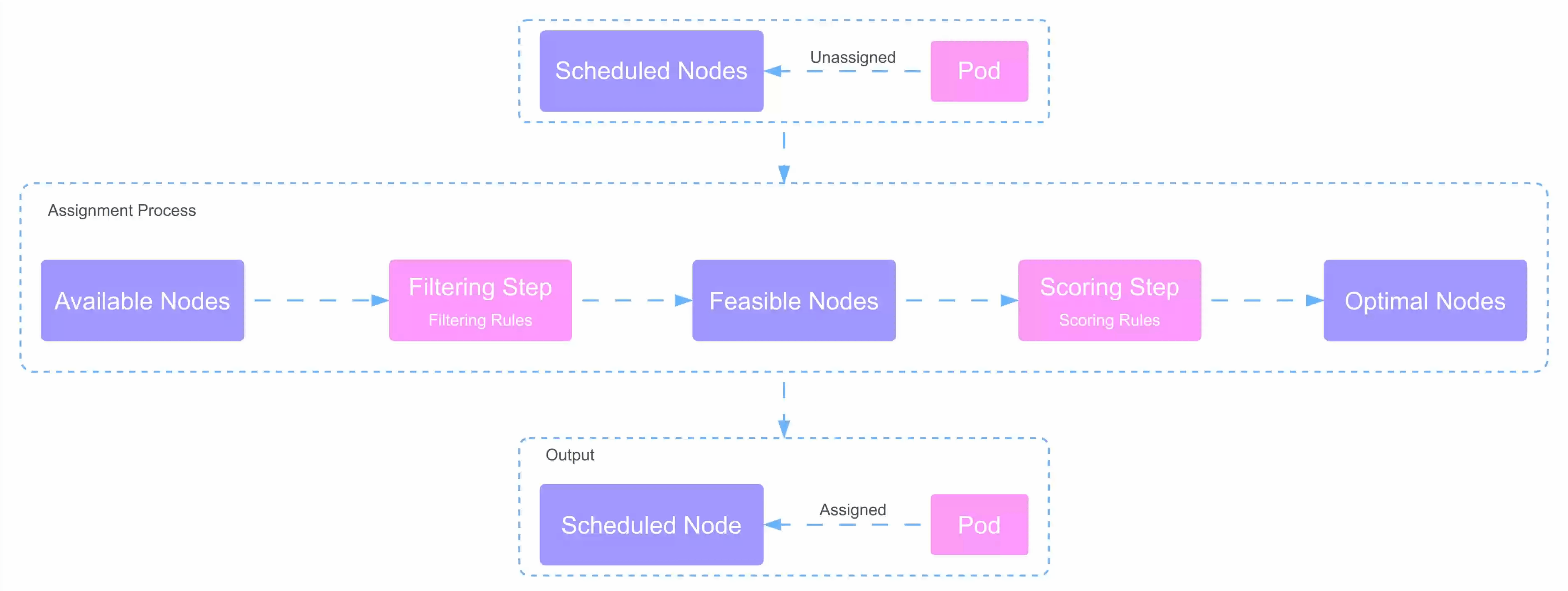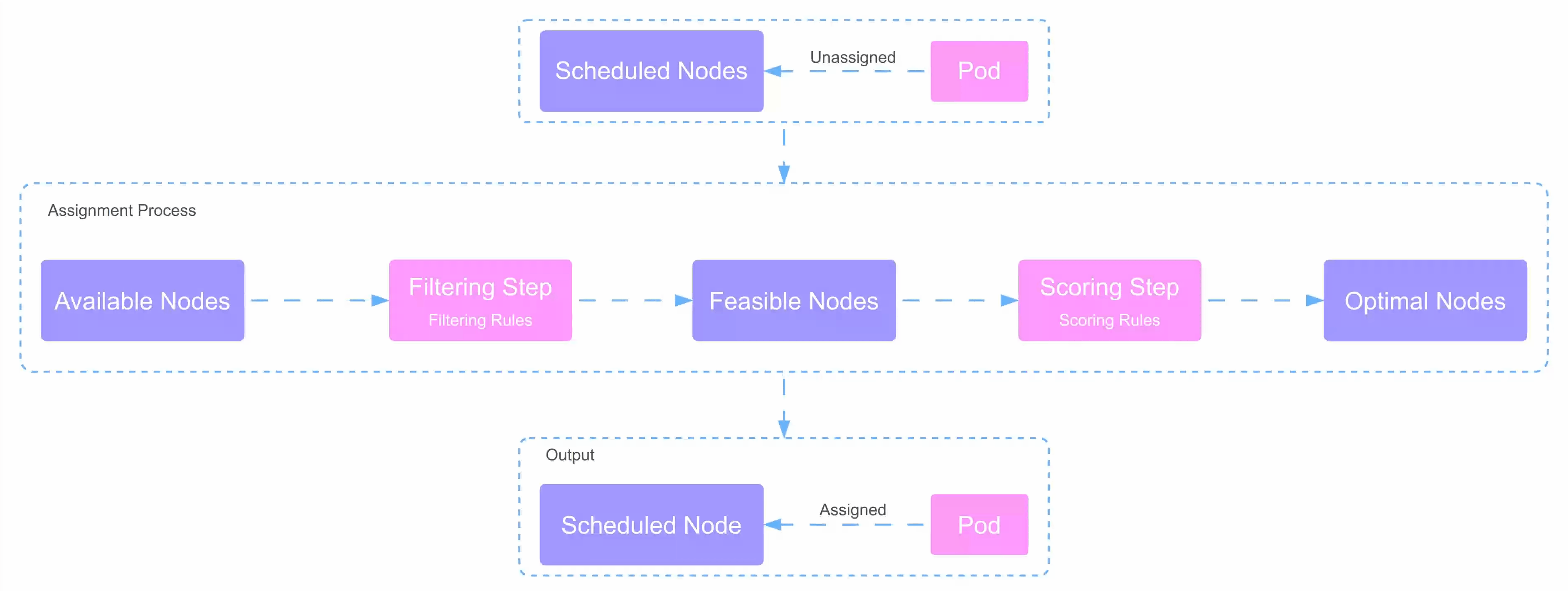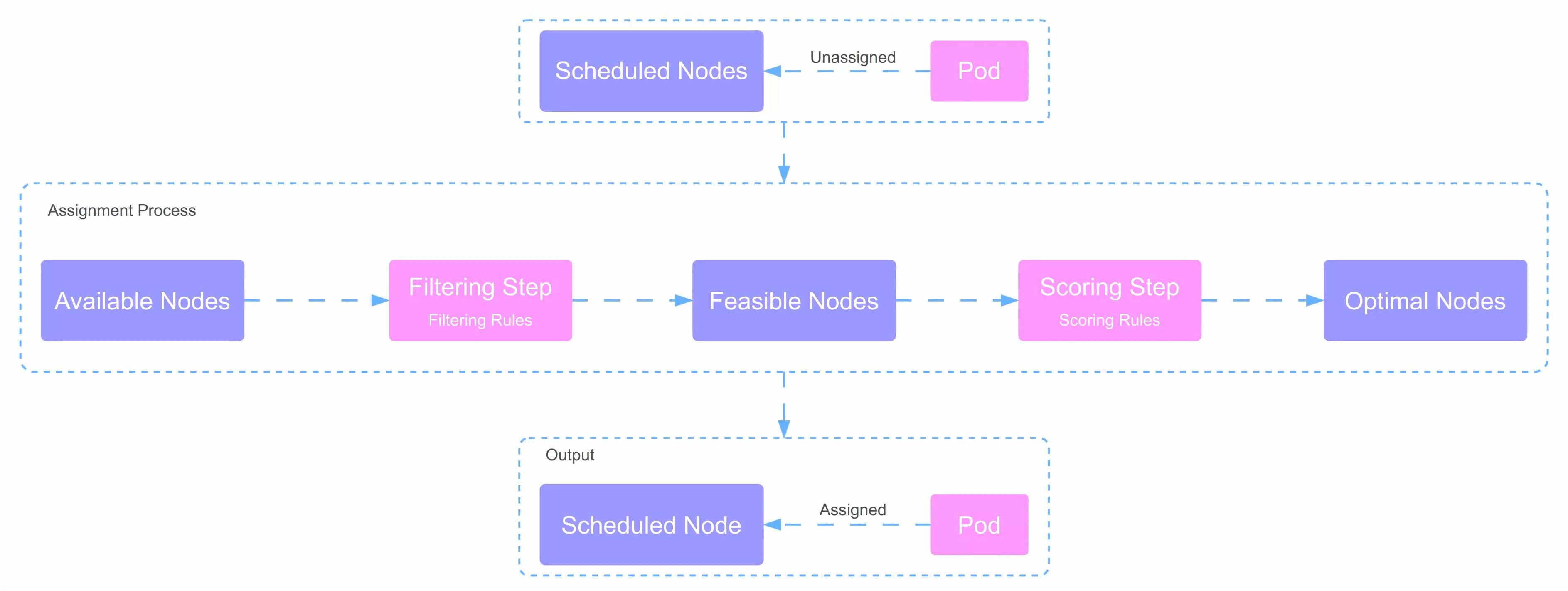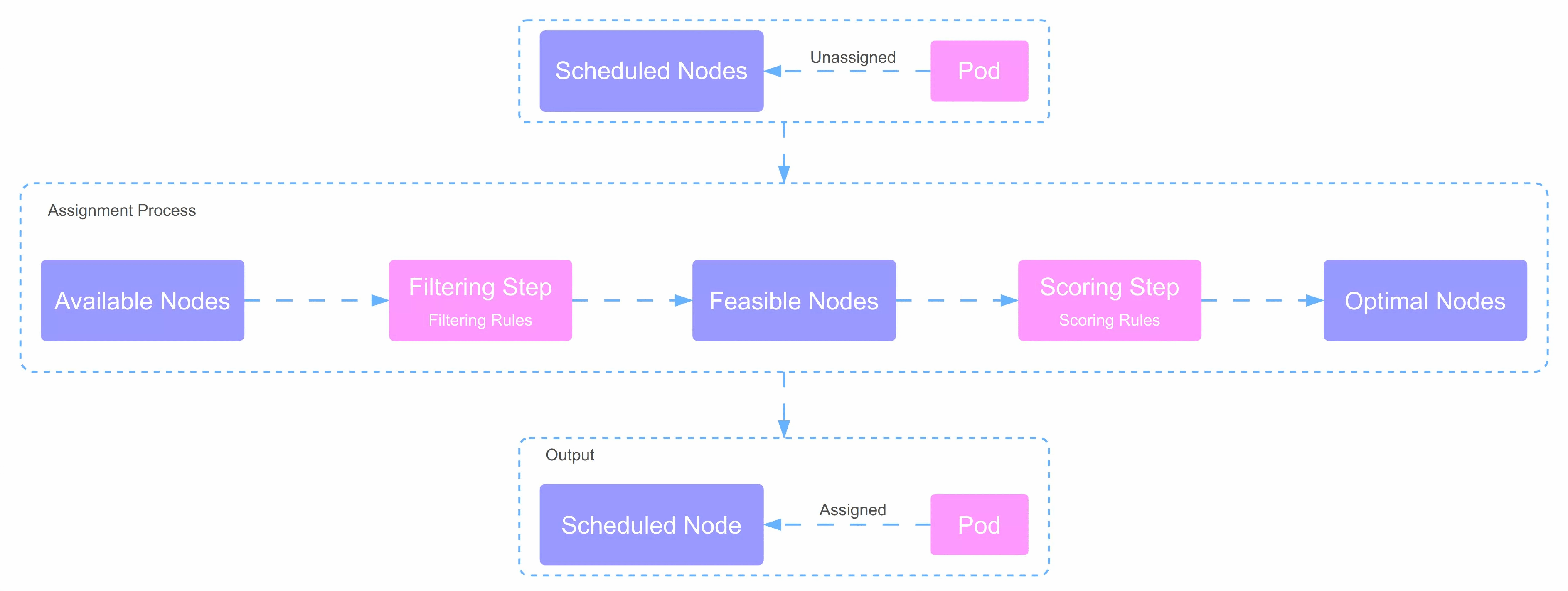
The Kubernetes scheduler is responsible for assigning new Pods to suitable nodes, a process known as Automated Placement. This process takes into account container resource requests and scheduling policies.
In a microservices-based system, there can be numerous isolated processes. Containers and Pods provide packaging and deployment abstractions, but they don’t solve the placement problem on appropriate nodes. That’s where the Kubernetes scheduler comes in. It retrieves each new Pod definition from the API Server and assigns it to a node considering runtime dependencies, resource requirements, and high availability policies.
Key aspects of Kubernetes scheduling:
- Node Resource Availability: The scheduler ensures that the total resources requested by a Pod’s containers don’t exceed the node’s available capacity. If resources are not reserved for system daemons, Pods can be scheduled up to the node’s full capacity, potentially leading to resource starvation issues
- Container Resource Requirements: For efficient Pod placement, containers should declare their resource profiles and environment dependencies. This allows Pods to be optimally assigned to nodes and run without affecting each other or facing resource starvation during peak usage
- Scheduler Configurations: The scheduler can be configured to meet your cluster needs using profiles that allow you to override the default implementations of the scheduling process
- Scheduling Process: Pods are assigned to nodes based on placement policies. The scheduler applies filtering policies and removes nodes that do not qualify. The remaining nodes are scored and ordered by weight. The scheduler then informs the API server about the assignment decision
While it’s generally better to let the scheduler handle Pod-to-Node assignment, you may want to force a Pod’s assignment to a specific node using a node selector. Node Affinity in Kubernetes allows for more flexible scheduling configurations by enabling rules to be either required or preferred.

Pod Affinity is a scheduling method in Kubernetes that allows you to limit which nodes a Pod can run on based on label or field matching. It can express rules at various topology levels based on the Pods already running on a node.
Topology Spread Constraints provide precise control for evenly distributing Pods across your cluster to achieve better cluster utilization or high availability of applications.
Impurities and acceptances are advanced features that control Pod scheduling. Impurities are node attributes that prevent Pods from being scheduled on the node unless the Pod has an acceptance for the impurity.
The Kubernetes descheduler helps in defragmenting nodes and enhancing their utilization. It’s run as a Job by a cluster administrator to tidy up and defragment a cluster by rescheduling the Pods.
Placement is the process of assigning Pods to nodes. In complex scenarios, Pods may be scheduled to specific nodes based on constraints like data locality, Pod colocality, application high availability, and efficient cluster resource utilization.
There are several methods to guide the scheduler towards your preferred deployment topology: nodeName, nodeSelector, Node affinity, and Taints and tolerations. Once you’ve expressed your preferred correlation between a Pod and nodes, identify dependencies between different Pods. Use Pod affinity techniques for colocation of tightly coupled applications, and use Pod anti-affinity techniques to distribute Pods across nodes and avoid single points of failure.
To use topology spread constraints, admins must label nodes with topology data. Workload authors must then be aware of this topology when creating Pod configurations.
The default scheduler places new Pods onto nodes and can be altered in the filtering and prioritization phases. If this isn’t enough, a custom scheduler can be created. This allows for consideration of factors outside of the Kubernetes cluster when assigning Pods to nodes.
Conclusion
Kubernetes Foundational Patterns provide a common language and structure for building and deploying applications on Kubernetes. These patterns help developers understand how to build and deploy applications in a consistent and efficient manner, and provide guidelines for building and deploying scalable, reliable, and maintainable applications. By using Kubernetes Foundational Patterns, developers can improve collaboration, support, and security, and reduce the risk of errors and inconsistencies.
